Please visit
allegrograph.com/blog
for the latest posts.
Friday, March 27, 2020
Wednesday, May 2, 2018
Triple Attributes
The Most Secure Graph Database Available
Triples offer a way of describing model elements and relationships between them. In come cases, however, it is also convenient to be able to store data that is associated with a triple as a whole rather than with a particular element. For instance one might wish to record the source from which a triple has been imported or access level necessary to include it in query results. Traditional solutions of this problem include using graphs, RDF reification or triple IDs. All of these approaches suffer from various flexibility and performance issues. For this reason AllegroGraph offers an alternative: triple attributes.
Attributes are key-value pairs associated with a triple. Keys refer to attribute definitions that must be added to the store before they are used. Values are strings. The set of legal values of an attribute can be constrained by the definition of that attribute. It is possible to associate multiple values of a given attribute with a single triple.
Possible uses for triple attributes include:
- Access control: It is possible to instruct AllegroGraph to prevent an user from accessing triples with certain attributes.
- Sharding: Attributes can be used to ensure that related triples are always placed in the same shard when AllegroGraph acts as a distributed triple store.
Like all other triple components, attribute values are immutable. They must be provided when the triple is added to the store and cannot be changed or removed later.
To illustrate the use of triple attributes we will construct an artificial data set containing a log of information about contacts detected by a submarine at a single moment in time.
Managing attribute definitions
Before we can add triples with attributes to the store we must create appropriate attribute definitions.
First let’s open a connection
Attribute definitions are represented by
AttributeDefinition objects. Each definition has a name, which must be unique, and a few optional properties (that can also be passed as constructor arguments):
allowed_values: a list of strings. If this property is set then only the values from this list can be used for the defined attribute.ordered: a boolean. If true then attribute value comparisons will use the ordering defined byallowed_values. The default is false.minimum_number,maximum_number: integers that can be used to constrain the cardinality of an attribute. By default there are no limits.
Let’s define a few attributes that we will later use to demonstrate various attribute-related capabilities of AllegroGraph. To do this, we will use the
setAttributeDefinition() method of the connection object.
It is possible to retrieve the list of attribute definitions from a repository by using the
getAttributeDefinitions() method:
Notice that in cases where the maximum cardinality has not been explicitly defined, the server replaced it with a default value. In practice this value is high enough to be interpreted as ‘no limit’.
Attribute definitions can be removed (provided that the attribute is not used by the static attribute filter, which will be discussed later) by calling
deleteAttributeDefinition():Adding triples with attributes
Now that the attribute definitions have been established we can demonstrate the process of adding triples with attributes. This can be achieved using various methods. A common element of all these methods is the way in which triple attributes are represented. In all cases dictionaries with attribute names as keys and strings or lists of strings as values are used.
When
addTriple() is used it is possible to pass attributes in a keyword parameter, as shown below:
The
addStatement() method works in similar way. Note that it is not possible to include attributes in the Statement object itself.
When adding multiple triples with
addTriples() one can add a fifth element to each tuple to represent attributes. Let us illustrate this by adding an aircraft to our dataset.
When all or most of the added triples share the same attribute set it might be convenient to use the
attributes keyword parameter. This provides default values, but is completely ignored for all tuples that already contain attributes (the dictionaries are not merged). In the example below we add a triple representing an aircraft carrier and a few more triples that specify its position. Notice that the first triple has a lower security level and multiple sources. The common ‘contact’ attribute could be used to ensure that all this data will remain on a single shard.
Another method of adding triples with attributes is to use the NQX file format. This works both with
addFile() and addData() (illustrated below):
When importing from a format that does not support attributes, it is possible to provide a common set of attribute values with a keyword parameter:
The data above represents six visually observed Walrus-class submarines, flying at different altitudes and well above the speed of light. It has been highly classified to conceal the fact that someone has clearly been drinking while on duty - after all there are only four Walrus-class submarines currently in service, so the observation is obviously incorrect.
Retrieving attribute values
We will now print all the data we have added to the store, including attributes, to verify that everything worked as expected. The only way to do that is through a SPARQL query using the appropriate magic property to access the attributes. The query below binds a literal containing a JSON representation of triple attributes to the ?a variable:
The result contains all the expected triples with pretty-printed attributes.
Attribute filters
Triple attributes can be used to provide fine-grained access control. This can be achieved by using static attribute filters.
Static attribute filters are simple expressions that control which triples are visible to a query based on triple attributes. Each repository has a single, global attribute filter that can be modified using
setAttributeFilter(). The values passed to this method must be either strings (the syntax is described in the documentation of static attribute filters) or filter objects.
Filter objects are created by applying set operators to ‘attribute sets’. These can then be combined using filter operators.
An attribute set can be one of the following:
- a string or a list of strings: represents a constant set of values.
- TripleAttribute.name: represents the value of the name attribute associated with the currently inspected triple.
- UserAttribute.name: represents the value of the name attribute associated with current query. User attributes will be discussed in more detail later.
Available set operators are shown in the table below. All classes and functions mentioned here can be imported from the
franz.openrdf.repository.attributes package:| Syntax | Meaning |
|---|---|
Empty(x) | True if the specified attribute set is empty. |
Overlap(x, y) | True if there is at least one matching value between the two attribute sets. |
Subset(x, y), x << y | True if every element of x can be found in y |
Superset(x, y), x >> y | True if every element of y can be found in x |
Equal(x, y), x == y | True if x and y have exactly the same contents. |
Lt(x, y), x < y | True if both sets are singletons, at least one of the sets refers to a triple or user attribute, the attribute is ordered and the value of the single element of x occurs before the single value of y in the lowed_values list of the attribute. |
Le(x, y), x <= y | True if y < x is false. |
Eq(x, y) | True if both x < y and y < x are false. Note that using the == Python operator translates toEqauls, not Eq. |
Ge(x, y), x >= y | True if x < y is false. |
Gt(x, y), x > y | True if y < x. |
Note that the overloaded operators only work if at least one of the attribute sets is a
UserAttribute or TripleAttribute reference - if both arguments are strings or lists of strings the default Python semantics for each operator are used. The prefix syntax always produces filters.
Filters can be combined using the following operators:
| Syntax | Meaning |
|---|---|
Not(x), ~x | Negates the meaning of the filter. |
And(x, y, ...), x & y | True if all subfilters are true. |
Or(x, y, ...), x | y | True if at least one subfilter is true. |
Filter operators also work with raw strings, but overloaded operators will only be recognized if at least one argument is a filter object.
Using filters and user attributes
The example below displays all classes of vessels from the dataset after establishing a static attribute filter which ensures that only sonar contacts are visible:
The output contains neither the visually observed Walruses nor the radar detected ASW helicopter.
To avoid having to set a static filter before each query (which would be inefficient and cause concurrency issues) we can employ user attributes. User attributes are specific to a particular connection and are sent to the server with each query. The static attribute filter can refer to these and compare them with triple attributes. Thus we can use code presented below to create a filter which ensures that a connection only accesses data at or below the chosen clearance level.
We can see that the output here contains only contacts with the access level of low. It omits the destroyer and Alpha submarine (these require medium level) as well as the top-secret Walruses.
The main advantage of the code presented above is that the filter can be set globally during the application setup and access control can then be achieved by varying user attributes on connection objects.
Let us now remove the attribute filter to prevent it from interfering with other examples. We will use the
clearAttributeFilter() method.
It might be useful to change connection’s attributes temporarily for the duration of a single code block and restore prior attributes after that. This can be achieved using the
temporaryUserAttributes() method, which returns a context manager. The example below illustrates its use. It also shows how to use getUserAttributes() to inspect user attributes.Wednesday, March 7, 2018
Allegro "Knowledge" Graph News - March 2018
In this issue
- Webcast - Navigating Time and Probability in Knowledge Graphs
- Webcast - A Juypter Notebook for Learning AllegroGraph (Bonus n-Dimensional GeoSpatial)
- InfoWorld article - The marvels of an event-based schema
- AllegroGraph 6.4.1 - Now Available
- Gruff v7.2.1 - Now Available
- IEEE Publication - Transmuting Information to Knowledge with an Enterprise Knowledge Graph
- Enterprise Data World - Taking Graphs to the Next Level with Artificial Intelligence and Machine Learning - April 22-27, 2018
- Franz Inc. - Named to Trend-Setting Products in Data and Information Management for 2018 by Database Trends and Applications
- Analytics Week article - The Secret to Business Users Understanding Big Data: Enterprise Taxonomies
- InfoWorld article - Harmonizing big data with an enterprise knowledge graph
- Dataconomy article - Triple Attributes: A New Way to Protect the Most Sensitive Information
- Follow us on Google Plus, Twitter, LinkedIn, and YouTube
- Recent Articles
Webcast - Navigating Time and Probability in Knowledge Graphs

Thursday, March 22 at 11AM Pacific
The market for knowledge graphs is rapidly developing and evolving to solve widely acknowledged deficiencies with data warehouse approaches. Graph databases are providing the foundation for these knowledge graphs and in our enterprise customer base we see two approaches forming: static knowledge graphs and dynamic event driven knowledge graphs.
Static knowledge graphs focus mostly on metadata about entities and the relationships between these entities but they don’t capture ongoing business processes. DBPedia, Geonames and Census or Pubmed are great examples of static knowledge. Dynamic knowledge graphs are used in the enterprise to facilitate internal processes, facilitate the improvement of products or services or gather dynamic knowledge about customers.
Dr. Aasman recently authored an IEEE article describing this evolution of knowledge graphs in the Enterprise and during this presentation we will describe two critical success factors for dynamic knowledge graphs, a uniform way to model, query and interactively navigate time and the power of incorporating probabilities into the graph. The presentation will cover three use cases and live demos showing the confluence of knowledge via machine learning, visual querying, distributed graph databases, and big data not only displays links between objects, but also quantifies the probability of their occurrence.
To register for this webinar, see here
The IEEE Paper Link
Webcast - A Juypter Notebook for Learning AllegroGraph (Bonus n-Dimensional GeoSpatial)
The Jupyter Notebook is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations and narrative text.
Join us to learn more about the examples available with AllegroGraph's new Python tutorial using Jupyter Notebook for interactive learning.
To register for this webinar, see here
InfoWorld article - The marvels of an event-based schema

When working with various data types at the speed of big data, this method is ideal for integrating and aggregating assorted information for the holistic value it provides.
The issue of schema—and what is frequently perceived as its inherent difficulties—is becoming more important every day. Organizations are increasingly encountering decentralized computing environments typified by semi-structured or unstructured external data of varying formats, often requiring integration with internal, structured data for immediate business value...
To read the full article, see here
AllegroGraph 6.4.1 - Now Available
New Features Include:
AllegroGraph Multi-master Replication is a real-time transactionally consistent data replication solution. It allows businesses to move and synchronize their semantic data across the enterprise. This facilitates real-time reporting, load balancing, and disaster recovery.
|
For additional information, see here
Gruff v7.2.1 - Now Available
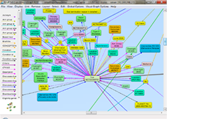
New Features Include:
Gruff’s new 'Time Machine' feature provides users an important capability to explore temporal connections in your data. This capability lets you see how relationships are created over time and are you are able to replay the evolving graph for new temporal based insights."
Gruff produces dynamic data visualizations that organize connections between data in views that are driven by the user. This visual flexibility can instantly unveil new discoveries and knowledge that turn complex data into actionable business insights. Gruff was developed by Franz to address Graph Search in large data sets and empower users to intelligently explore graphs in multiple views including:
- Graphical View with new “Time Machine” feature - See the shape and density of graph data evolve over time
- Tabular view - Understand objects as a whole
- Outline view - Explore the often hierarchical nature of graphs
- Query view - Write Prolog or SPARQL queries
- Graphical Query Builder - Create queries visually via drag and drop
For additional information, see the Gruff Documentation
IEEE Publication - Transmuting Information to Knowledge with an Enterprise Knowledge Graph

The enterprise knowledge graph for entity 360-views has emerged as one of the most useful graph database technology applications when buttressed by W3C standard semantic technology, modern artificial intelligence, and visual discovery tools. Read this IEEE publication by Dr. Jans Aasman to learn more about Knowledge Graphs.
For additional information, see here
Enterprise Data World - Taking Graphs to the Next Level with Artificial Intelligence and Machine Learning - April 22-27, 2018
The 22nd Annual Enterprise Data World (EDW) Conference hosted by DATAVERSITY® is recognized as the most comprehensive educational conference on data management in the world. Join hundreds of data professionals from around the globe to attend this unique conference. Your transformation to data-driven business starts here!
Franz CEO Jans Aasman will be presenting "Taking Graphs to the Next Level with Artificial Intelligence and Machine Learning".
Graphs and Knowledge Management have gained significant visibility with the rebirth of artificial intelligence and emergence of cognitive computing. By combining artificial intelligence, big data, graph databases, and dynamic visualizations, we will discuss deploying Graph based AI applications as a means to help predict future events across numerous types of industries.
Knowledge creation via AI and Graphs stems from the capability to combine the probability space (i.e. statistical inference on a user’s data) with a knowledge base of comprehensive industry terminology systems. AI using Graphs are remarkable not just because of the possibilities they engender, but also because of their practicality. The confluence of knowledge via machine learning, visual querying, graph databases, and big data not only displays links between objects, but also quantifies the probability of their occurrence. We believe this approach will be transformative across numerous business verticals.
During the presentation we will describe the Graph based AI concepts that also incorporate Hadoop, along with analytics via R, SPARK ML and other AI techniques for practical Enterprise predictive analytics use cases.
For additional information, see here
Franz Inc. - Named to Trend-Setting Products in Data and Information Management for 2018 by Database Trends and Applications

Today, innovative approaches, such as Hadoop, Spark, NoSQL, and NewSQL, are being used in addition to more established technologies, such as the mainframe, and relational and MultiValue database systems. In addition, artificial intelligence and machine learning capabilities are some of the newer approaches being introduced in products. To help bring these resources to light, each year, Database Trends and Applications magazine looks for offerings that promise to help organizations derive greater benefit from their data, make better decisions, work more efficiently, achieve greater security, and address emerging challenges. In total, this list of forward-looking products helps illuminate the path on which the data management market is headed.
For additional information, see:
- http://www.dbta.com/Editorial/Trends-and-Applications/Trend-Setting-Products-in-Data-and-Information-Management-for-2018-121846.aspx
- http://www.dbta.com/Editorial/Actions/Product-Spotlight-Franz-Inc-121893.aspx
Analytics Week article - The Secret to Business Users Understanding Big Data: Enterprise Taxonomies

The key to understanding big data doesn’t lie with some existent, or even forthcoming, application of Artificial Intelligence—although AI can certainly abet the process. Nor does it expressly relate to any facet of data science, blockchain, or decentralized computing application such as the Industrial Internet. Instead, the basis for modeling, integrating, governing, and even querying many of these manifestations of the data ecosystem lies with something much simpler: words.
Classifications of words and their hierarchies, taxonomies, are the rudiment to understanding big data’s meaning in terms business users comprehend. When such terminology systems span the enterprise, they create opportunities for the business to capitalize on big data’s underlying meaning, regardless of its form or the techniques used to access it...
To read the full article, see here
InfoWorld article - Harmonizing big data with an enterprise knowledge graph
In addition to streamlining how users retrieve diverse data via automation capabilities, a knowledge graph standardizes those data according to relevant business terms and models.
One of the most significant results of the big data era is the broadening diversity of data types required to solidify data as an enterprise asset. The maturation of technologies addressing scale and speed has done little to decrease the difficulties associated with complexity, schema transformation and integration of data necessary for informed action...
To read the full article, see here
Dataconomy article - Triple Attributes: A New Way to Protect the Most Sensitive Information

Semantic Graph Databases are now common in many industries, including life sciences, healthcare, the financial industry and in government and intelligence agencies. Graphs are particularly valuable in these sectors because of the complex nature of the data and need for powerful, yet flexible data analytics.
Attributes, user attributes and static filters are a new mechanism for graph databases to protect sensitive information. This combination provides the right amount of power and flexibility to address high-security use cases, such as: HIPAA access controls, privacy rules for banks, security models for policing, intelligence and the government. In addition, this set of methods is far easier to use, provides more expressiveness than security methods in relational databases and doesn’t suffer from performance degradations.
To read the full article, see here
Follow us on Google Plus, Twitter, LinkedIn, and YouTube
 |  |  |  |
Recent Articles about Franz
| |
 |
|
Subscribe to:
Posts (Atom)